はじめに
こんにちは。初めまして。
株式会社ビデオマーケットのサーバーサイドエンジニア、Haradanです!
業務としては、弊社で配信する作品の文字情報・画像を登録・管理するシステム、およびそれに関連する業務の保守・効率化に携わっています。
これまで既存システムの改修を中心に業務の改善を実現してきましたが、今回新たに「機械学習」を導入し、文字情報や画像のチェック作業など従来目視や人の経験に頼ってきた部分の効率化を進めるための取り組みを始めました。
このブログでは、その取り組みの一環として調査した「Google Cloud の機械学習プロダクト」について共有したいと思います。
機械学習とは
そもそも機械学習とは、コンピューターに既存のデータを読み込ませ、規則性を見出し、それをもとにした予測・分析を弾き出す手法のことを言います。
本来、この機械学習を活用するには高度な専門知識が必要となりますが、Google Cloud はそのような専門知識がなくとも機械学習を利用できるように、様々なプロダクトを提供しています。
Google Cloud の機械学習プロダクトとは
Google Cloud は、下記のように様々なデータに対して、機械学習プロダクトを提供しています。
各プロダクトの詳細については、下記リンクをご参照ください。
cloud.google.com
機械学習と画像データ
今回はその中でも画像データにフォーカスして説明していきます。
Google Cloud の機械学習プロダクトで画像データを扱う場合、大きく分けて以下の2種類の選択肢が存在します。
学習済みAPI
学習済みAPIとは、その名の通り学習済みのプロダクトで、すぐにでも使い始められるものです。
従来の機械学習ではまず、トレーニング用のデータを大量に用意し、それをコンピューターに学習させるという所から始める必要がありますが、学習済みAPIはそのような面倒な手順を省くことができます。
画像データ向け学習済みAPIとしては「Cloud Vision API」が用意されており、下記のような機能が提供されています。
- オブジェクトの検出
- ラベルの検出
- 不適切なコンテンツの検出
- etc...
以下のページより気軽に機能を試すことができます。
cloud.google.com
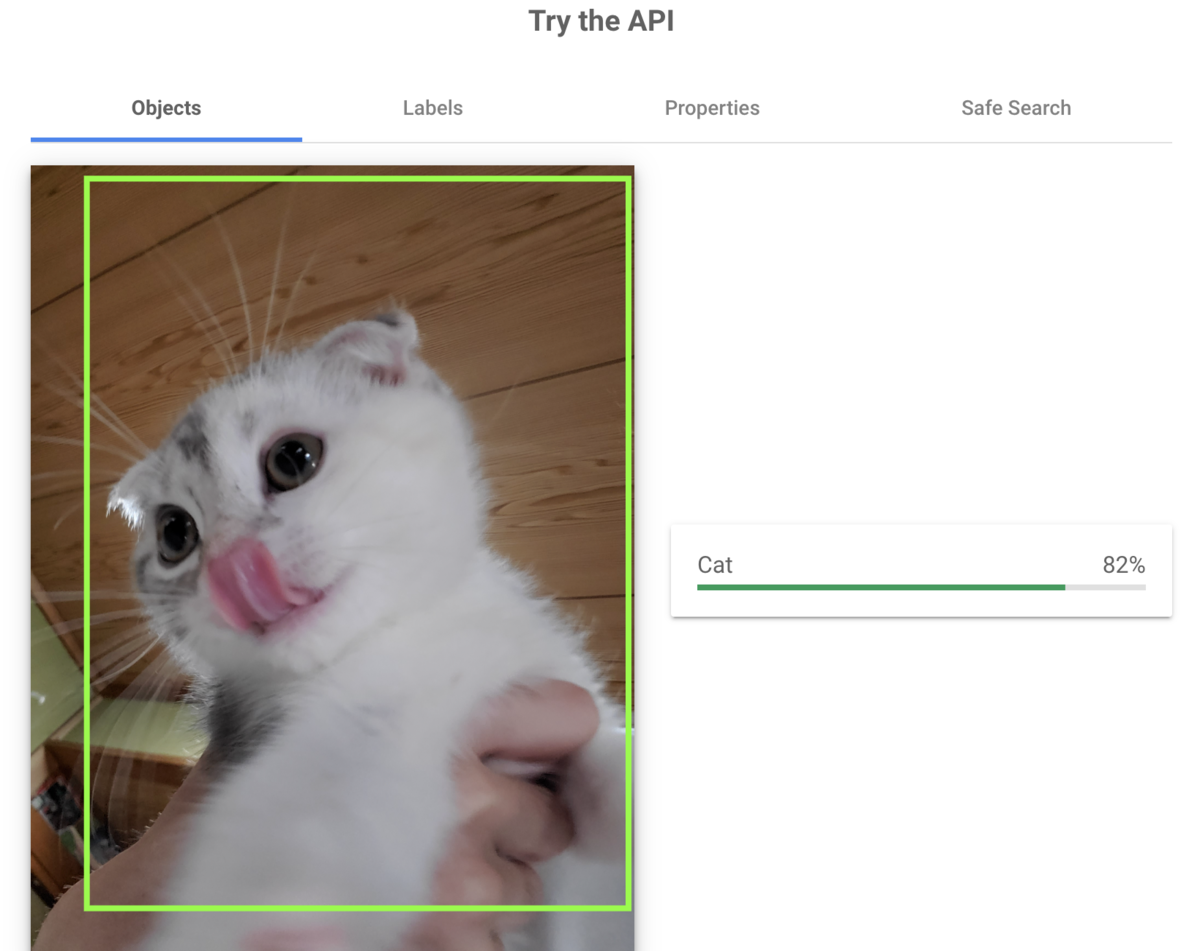
うちの猫に協力してもらい、早速 Cloud Vision API を試してみました。
「オブジェクトの検出」
「ラベルの検出」
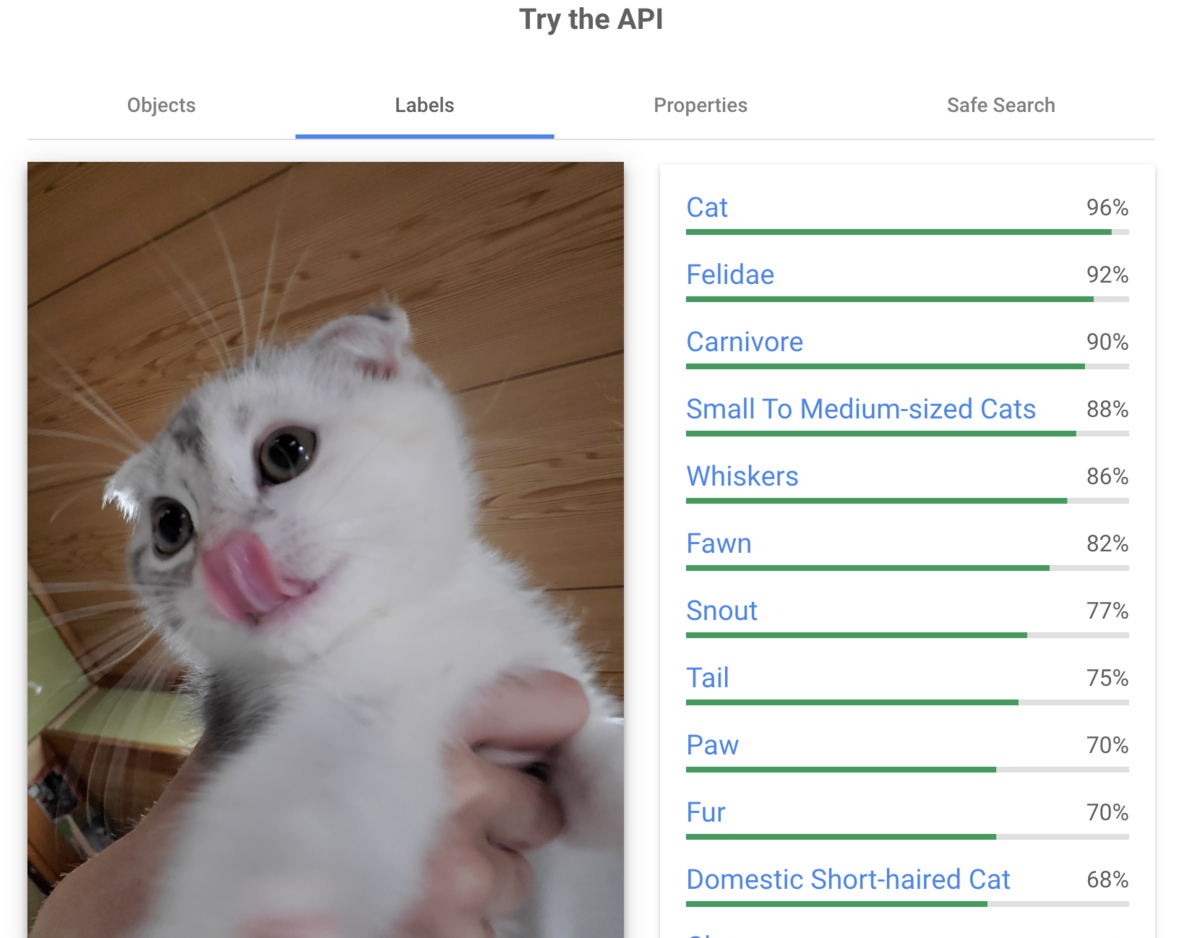
無事「Cat」と判定されていますね!
AutoML
学習済みAPIの場合、上記のように「犬」であるか「猫」であるかといったことを判定することはできますが、それが「どういう種類」なのかまでは判定できません。
このようなケースに対応できるのが、AutoMLです。
画像データ向けの機能としては、下記のものが提供されています。
例えば「画像の分類」機能を利用し、犬や猫の画像を種類ごとに用意してAutoMLに学習させることによって、「どういう種類」かを判定させることができます。
以下のページに公式のチュートリアルがあります。
cloud.google.com
実際に導入を検討する場合は、まず「学習済みAPI」が使用できないかを確認し、それでは対応できない場合に「AutoML」という流れで進めることをオススメします。
AutoMLによる画像の分類
ここからは、AutoMLの中でも「画像の分類」を実際に使用する流れについて紹介したいと思います。
※ 事前に以下のページをしっかりご確認のうえ、進めてください
cloud.google.com
全体の流れは以下の通りです。
- 分類対象の定義
- データの収集
- データのインポート
- インポートしたデータをもとにトレーニング
- トレーニングしたモデルをデプロイ
- デプロイしたモデルを使って予測する
順番に説明していきます。
1.分類対象の定義
はじめに、何について分類したいかを定義します。
今回は、再度うちの猫に協力してもらい、「撮った写真に猫が写っているか」を判定する機械学習モデルを作成することにしました。
次に、画像につけるラベルを定義します。
今回は以下のようにラベルを定義しました。
- 猫のいる画像 →「猫がいます」*1
- 猫のいない画像 →「猫はいないです」
「猫がいます」

「猫はいないです」

2.データの収集
分類したい対象を定義できたら、今度はトレーニング用の画像データを準備します。
今回はラベルごとに各100枚の画像を用意しました。*2
用意した画像をCloud Storage*3の任意のバケットにアップロード後、下記の形式でCSVファイルを作成し、こちらもCloud Storageへアップロードします。
1列目「アップロードした画像のgsutil URI」, 2列目「その画像につけるラベル」

3.データのインポート
Google Cloud のコンソールから Vertex AI > データセット へ移動します。
※ Vertex AI API が有効になっていない場合は、有効にしてください
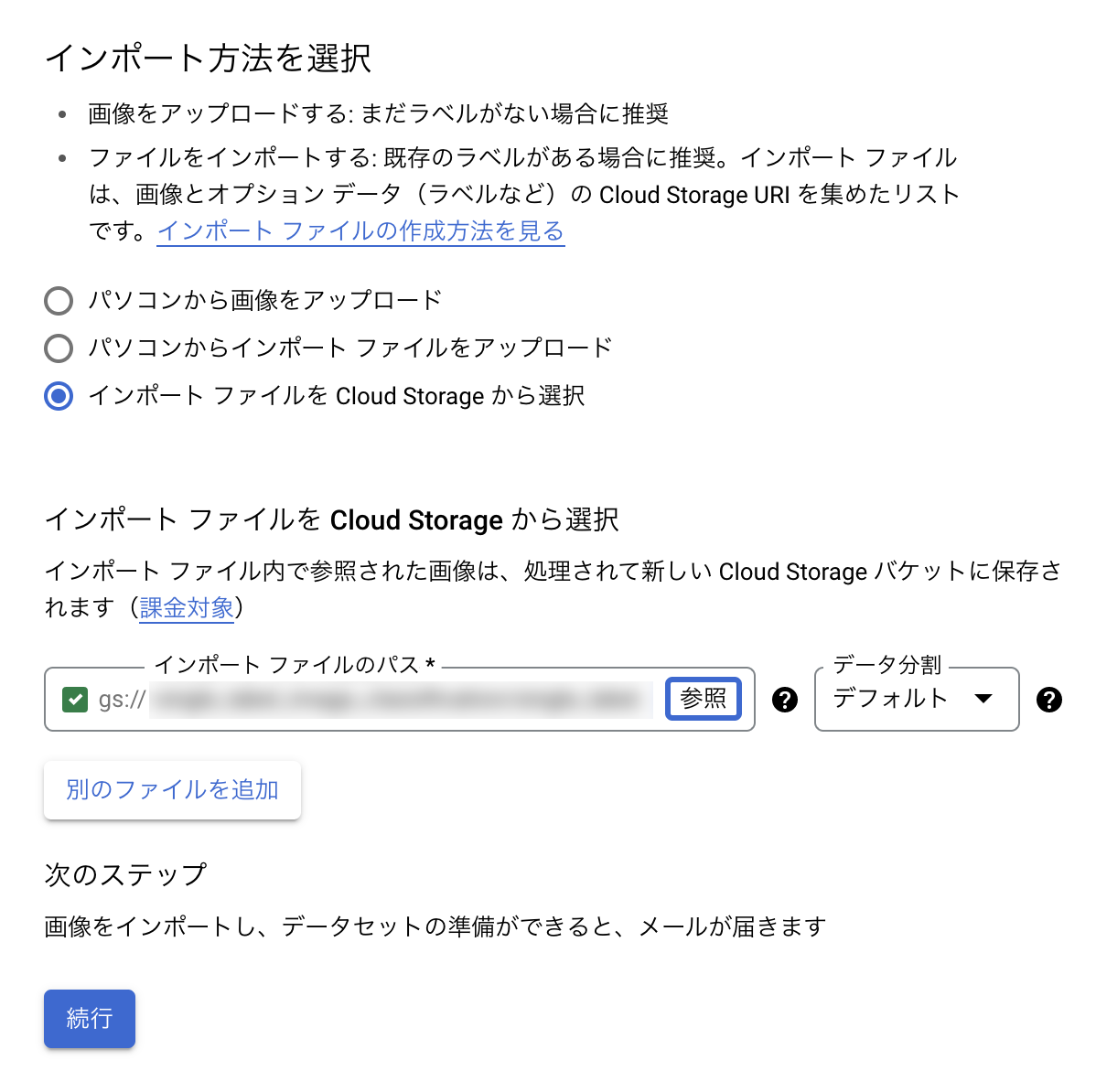
遷移先画面で「作成」をクリックすると、以下のような画面が出てくるので下記を設定し、「作成」をクリックします。
- データセット名:何でもOK
- データタイプと目標の選択:画像 > 画像分類(単一ラベル)
- リージョン:us-central1(アイオワ)以外は使用不可

次は以下のような画面が出てくるので下記を設定し、「続行」をクリックします。
画像のインポートが完了次第、メールでお知らせが届きます。
- インポート方法を選択:インポート ファイルを Cloud Storage から選択
- インポート ファイルのパス:2.でアップロードしたCSVファイルを指定
ラベルごとに画像がインポートされました。
「猫がいます」
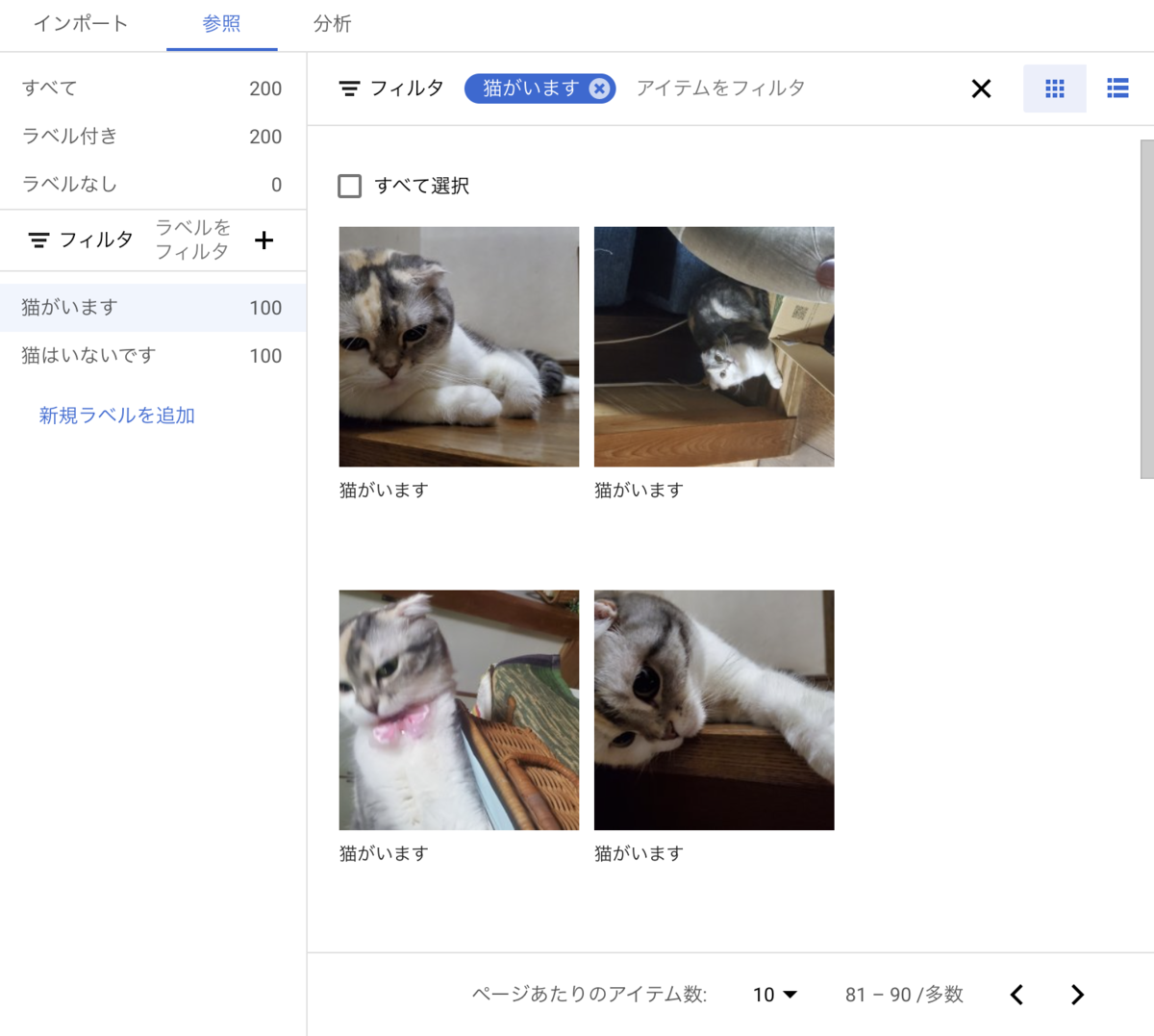
「猫はいないです」
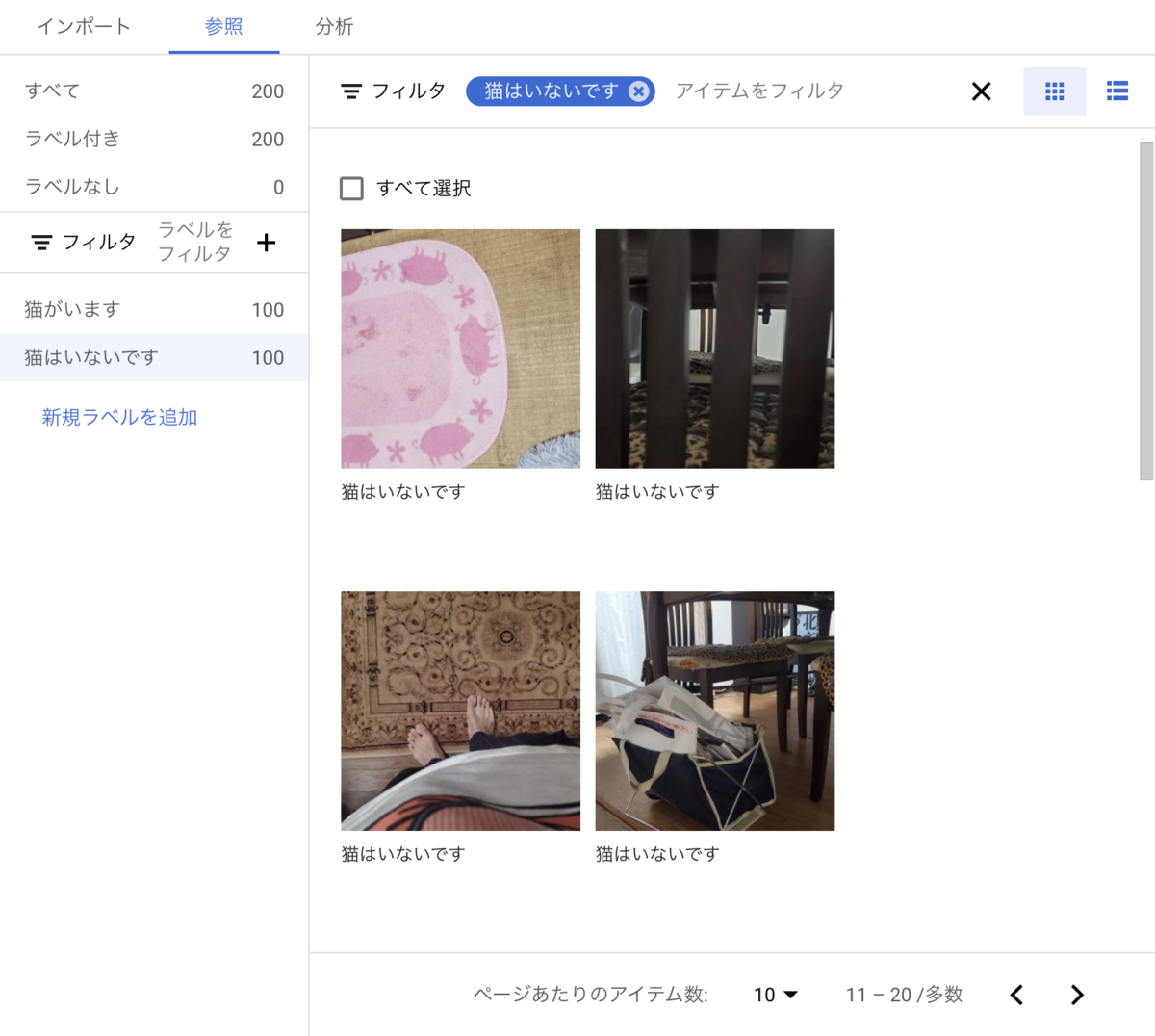
4.インポートしたデータをもとにトレーニング
次は、インポートした画像を使って、トレーニングを行なっていきます。
まず、上記インポート結果画面にある「新しいモデルをトレーニング」をクリックします。
遷移先画面で下記を設定し、「トレーニングを開始」をクリックします。
トレーニングが完了次第*4、メールでお知らせが届きます。
- Model training method:AutoML
- 新しいモデルをトレーニング(名前は何でもOK)
- 説明可能性*5:オフ
- 最大ノード時間:8(8〜800の間で入力)*6
- Enable early stopping:オン
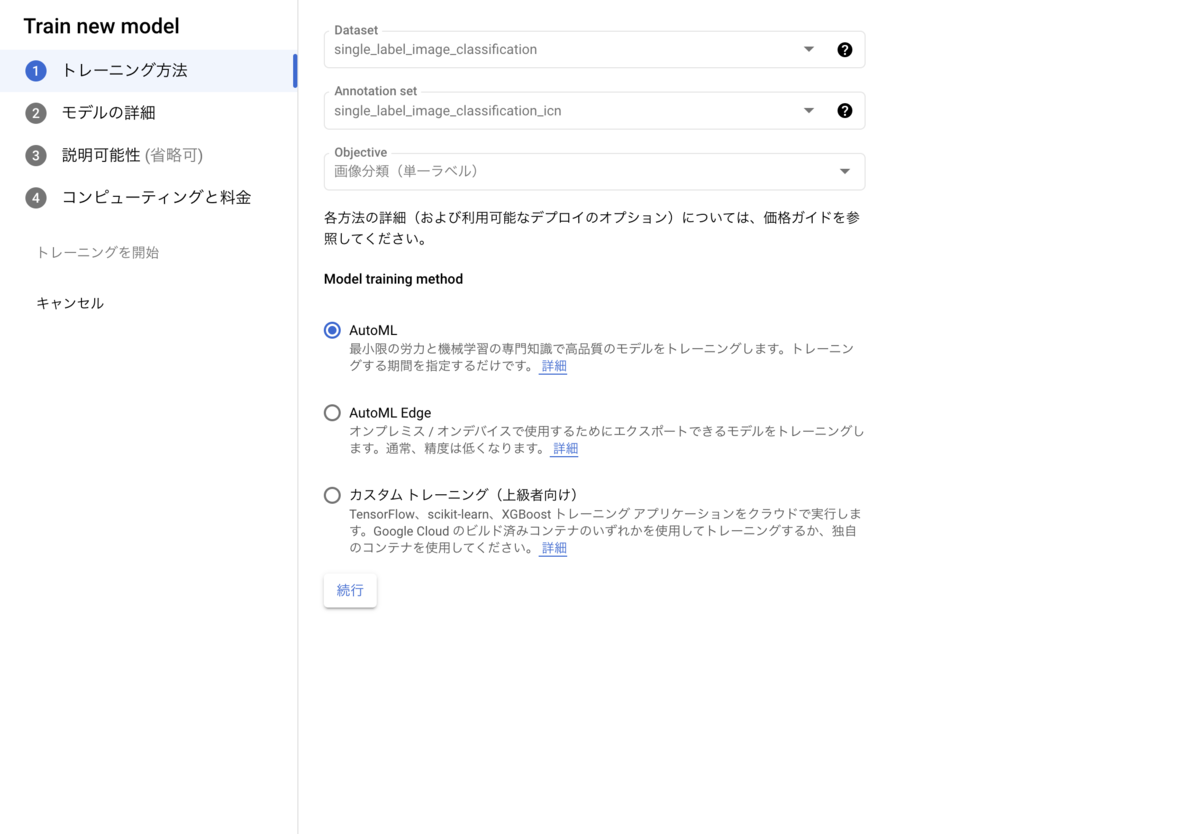
5.トレーニングしたモデルをデプロイ
トレーニングが完了したので、モデルをデプロイします。*7
Vertex AI > エンドポイント へ移動し、「エンドポイントを作成」をクリックします。
遷移先画面で下記を設定し、「作成」をクリックします。
- エンドポイント名:何でもOK
- アクセス:標準
- モデル名:4.で作成したモデル名を選択
- トラフィック分割:100
- コンピューティングのノードの数:1
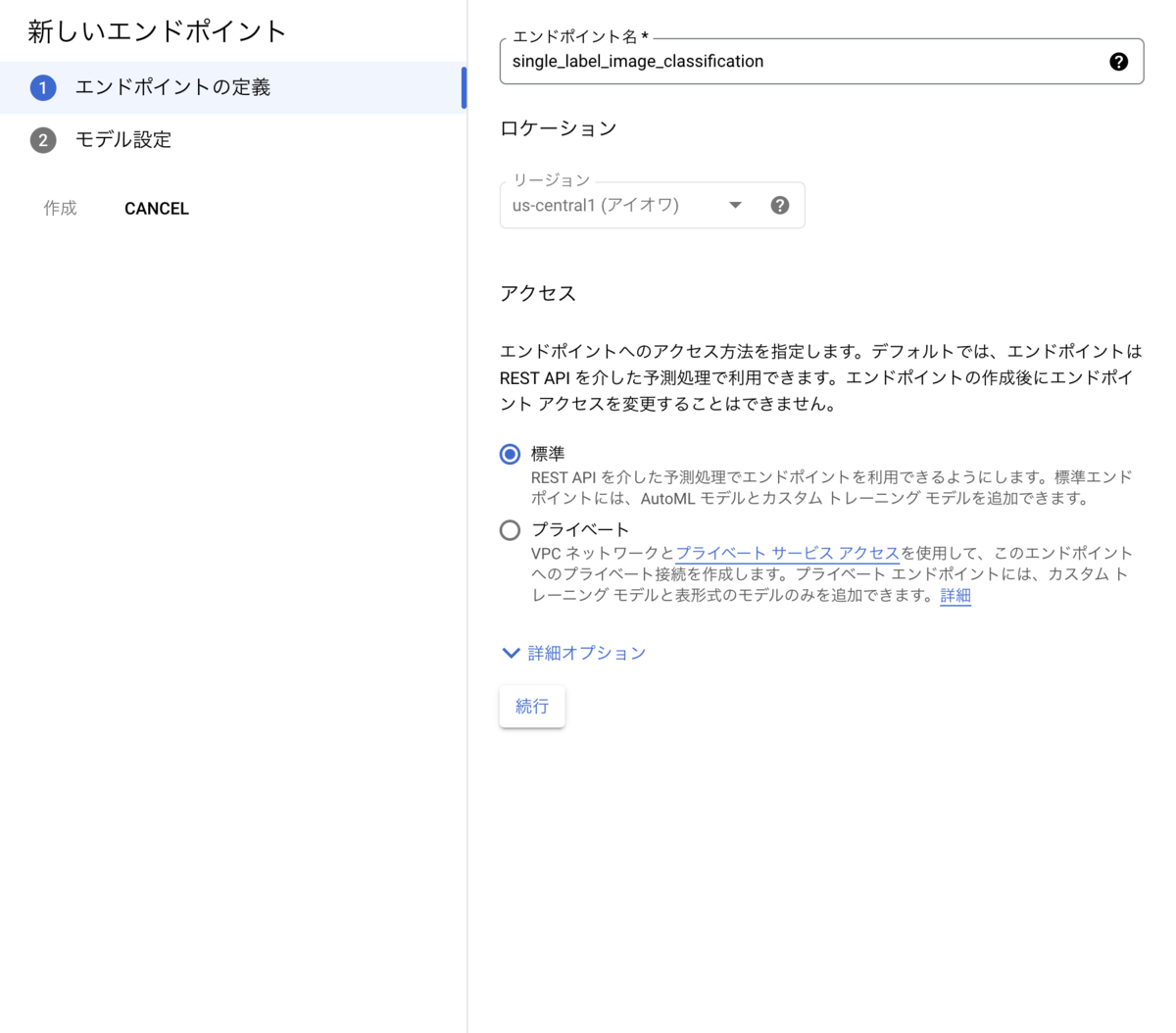
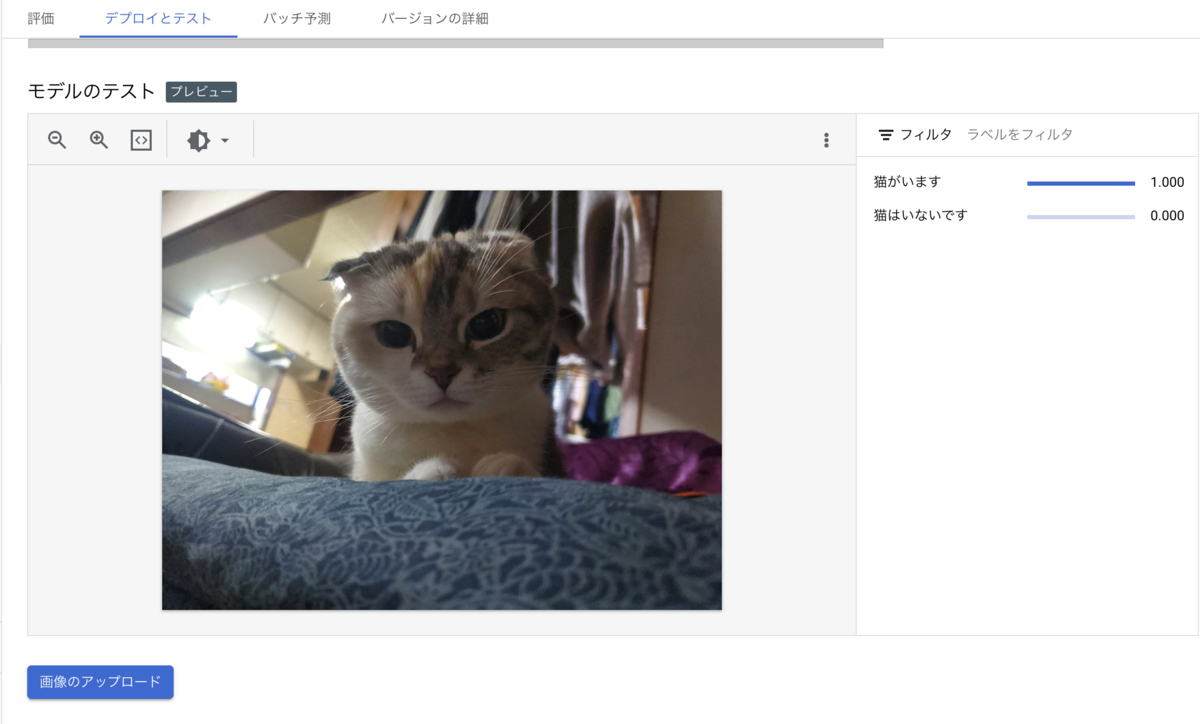
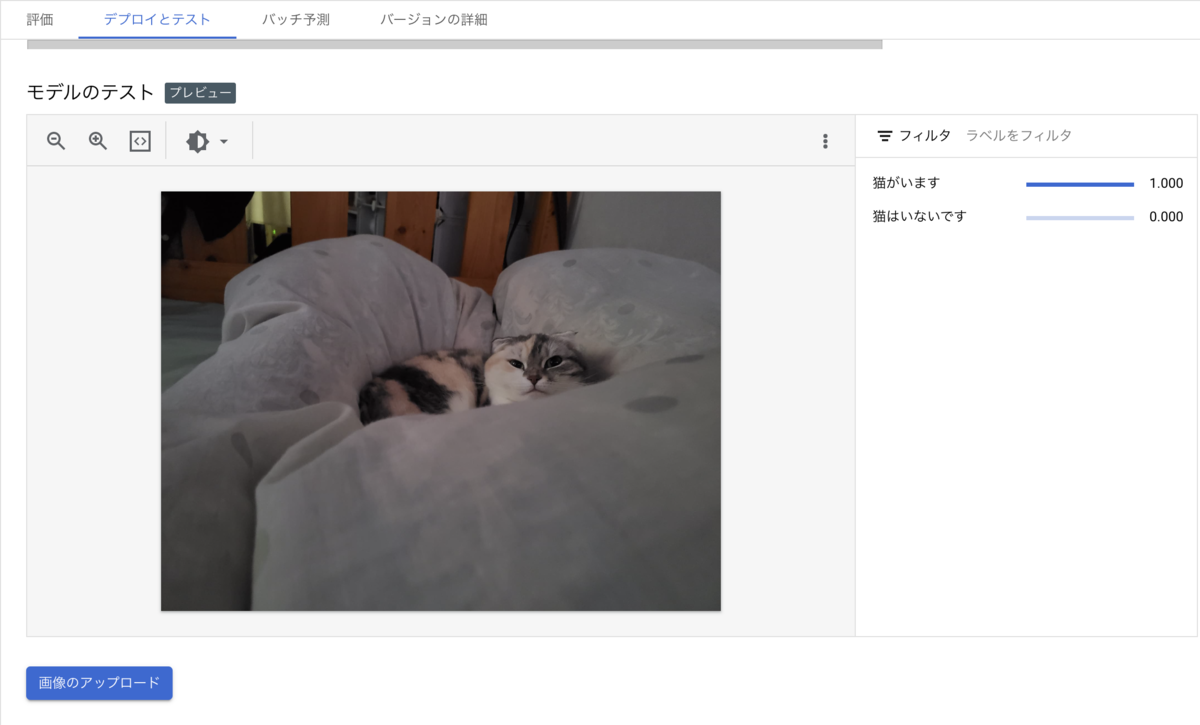
6. デプロイしたモデルを使って予測する
デプロイが完了したら、実際に予測をおこなってみます。
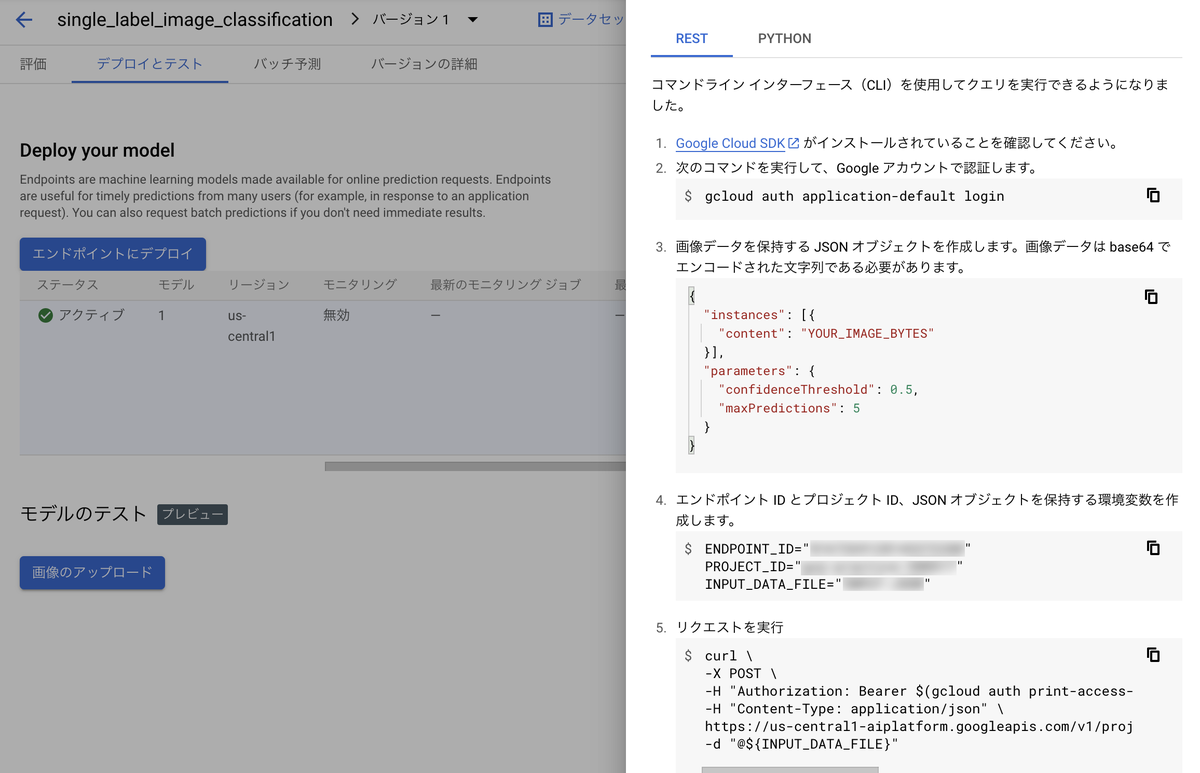
Vertex AI > エンドポイント より5.でデプロイしたモデル名をクリックし、遷移先ページの「デプロイとテスト」のタブを開きます。
そのページの「モデルのテスト」の項目より、画像をアップロードしてみます。
「猫がいます」
「猫はいないです」
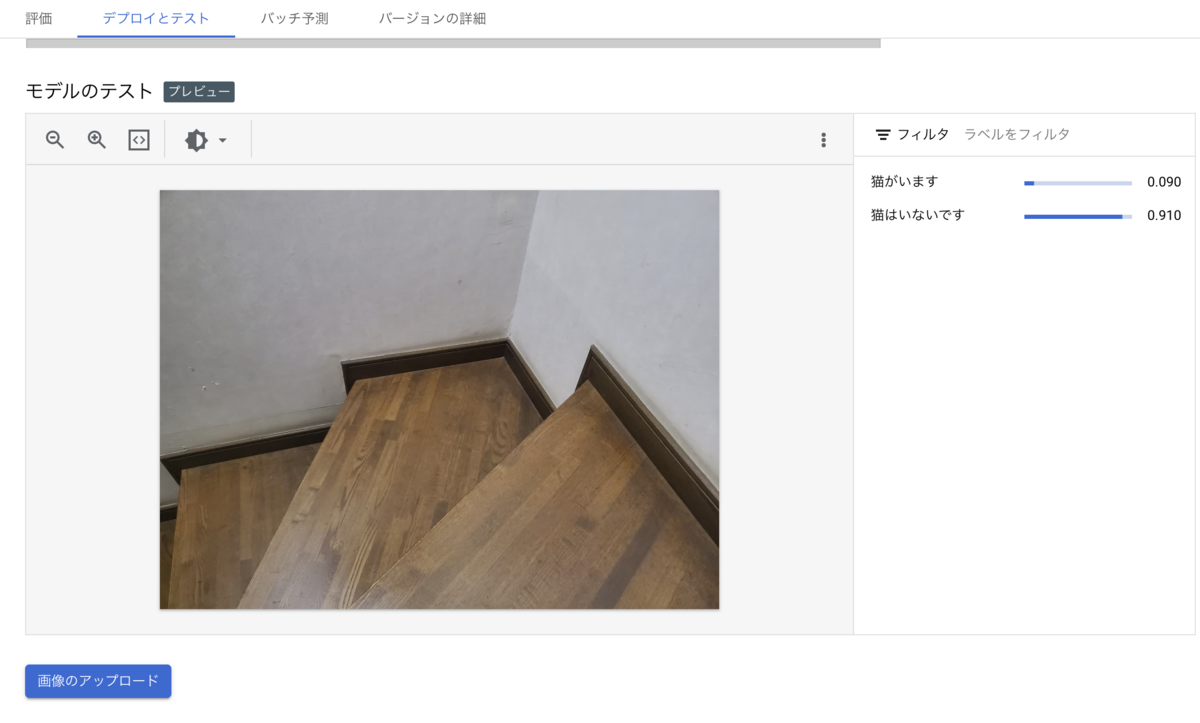
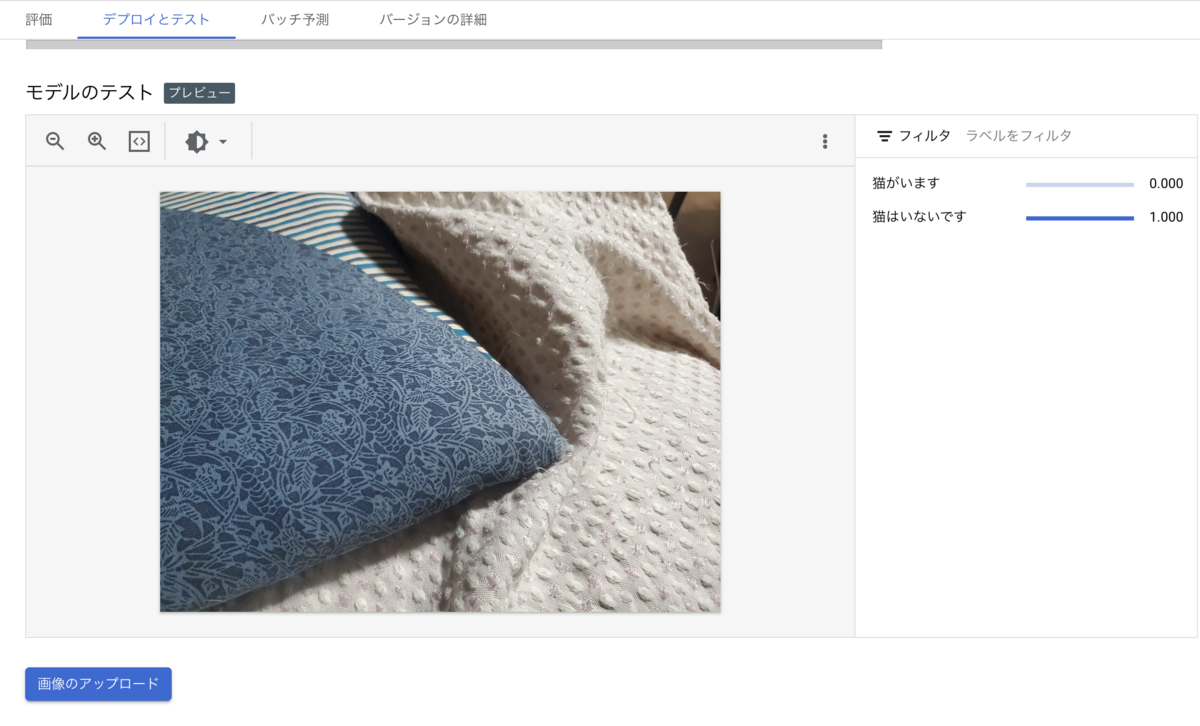
無事、判定できました!
こちらのデプロイしたエンドポイントはRESTやPythonなどで実行可能*8です。
使い終わったあとは、「エンドポイントからモデルのデプロイを解除」よりデプロイを解除することを忘れないようにしましょう。
予測が実行されなくても、エンドポイントにデプロイされている限り課金が発生します!
まとめ
いかがでしたでしょうか?
以上のように簡単に機械学習を使って画像の分類をすることができました!
弊社でもこちらをシステムに登録された画像の品質チェック作業などに活用予定です。
皆さんもぜひこういった機械学習プロダクトを活用してみてください!
リンク集
